A data-driven exploration of migrant identity trends
Collecting, analyzing, and presenting data for research conclusions
Stack
Python
VSCode
Excel
Google Forms
For my Master’s Thesis, I researched descendants of Croatian migrants in Chile—a migratory movement that took place at the end of the 19th and beginning of the 20th century—with the aim of observing how identity is constructed in post-migrant generations and the impacts Croatian citizenship legislation changes have had on this group.
For this, I designed and implemented an online survey that included three main areas: the first one focused on establishing demographic markers of the population; the second one delineated the awareness and perception of Croatian citizenship changes; and the last one aimed to learn about cultural engagement and identity. The survey was spread through the communities’ social media groups and through the Croatian diaspora in Chile, and it received a total of 182 responses.
Prepare data for analysis
The survey was carried out through Google Forms, which I then exported as an Excel file and analyzed using Visual Studio Code. In this editor, I worked with Jupyter Notebooks, writing each part of the code in different cells.
The survey contained different types of questions, such as short-answer, multiple-choice, long-answer, and linear scale. For this part of the analysis, which focused mostly on gathering quantitative insights, I decided to focus on short-answer and multiple-choice questions. Therefore, I first started by filtering the columns that contained the right types of answers and cleaning the data that contained Null values.
1import pandas as pd
2
3# Load the dataset
4data = pd.read_excel('Survey_data.xlsx')
5
6# Dropping columns with long-answer and Likert-scale responses
7columns_to_drop = [
8 '¿Es importante para usted tener ciudadanía croata? ¿Por qué?',
9 '¿Cuántas veces ha visitado Croacia?',
10 '¿Cree que la integración de Croacia a la Unión Europea influyó en su propia conexión con sus raíces?',
11 '¿A través de qué actividades siente que conecta con Croacia? ',
12 'Si quisiera participar de un seguimiento a sus respuestas, por favor escriba su correo electrónico en la casilla. Si no, simplemente omita esta pregunta.',
13 'Evalúe su conocimiento de idioma Croata en la escala de 1 (no hablo croata) a 5 (hablo fluido).',
14 'Evalúe su sentimiento de pertenencia a Croacia en la escala de 1 (no siento pertenencia) a 5 (siento pertenencia totalmente).',
15 'Evalúe su sentimiento de pertenencia a Chile en la escala de 1 (no siento pertenencia) a 5 (siento pertenencia totalmente).',
16 'Evalúe el impacto del ingreso de Croacia a la Unión Europea en la escala de 1 (no me impactó) a 5 (me impactó totalmente).'
17]
18
19data_cleaned = data.drop(columns=columns_to_drop)
20
21# Renaming columns with short answers
22rename_columns = {
23 '¿Cuál es su edad?': 'Age',
24 '¿Cuál es su género?': 'Gender',
25 '¿En qué parte de Chile vive?': 'Location',
26 '¿Quién fue su antepasado croata?': 'Ancestor',
27 '¿Está al tanto de las políticas de obtención de ciudadanía croata?': 'Citizenship_Awareness',
28 '¿Tiene ciudadanía Croata?': 'Citizenship_Status',
29 'Si su respuesta anterior fue sí, o en proceso de solicitud ¿cree que la eliminación requisitos para obtener ciudadanía croata en 2020 influyó en su decisión de realizar el proceso?': 'Citizenship_Influence',
30 '¿Forma parte de alguna organización Croata en Chile?': 'Participation'
31}
32
33data_cleaned = data_cleaned.rename(columns=rename_columns)
34
35# Print the new column names to confirm changes
36print("Updated columns:", data_cleaned.columns.tolist())
37
38# Save the cleaned data to a new Excel file
39data_cleaned.to_excel('Cleaned_Survey_Data.xlsx', index=False)Understanding the sample
As the first aim of the analysis, I wanted to get to know the characteristics of the group I’m researching. To achieve this, I first focused on the first group of questions:
1. How old are the respondents?
2. What gender do they identify with?
1# Exploratory data analysis of age and gender
2
3# Load the cleaned data
4df = pd.read_excel('Cleaned_Survey_Data.xlsx')
5
6# Translate 'Gender' column from Spanish to English
7gender_translation = {'Masculino': 'Male', 'Femenino': 'Female', 'Otro': 'Other'}
8df['Gender'] = df['Gender'].map(gender_translation)
9
10# Define the bins and labels for age grouping
11bins = [20, 30, 40, 50, 60, 70, 80, 90]
12labels = ['[20, 29]', '[30, 39]', '[40, 49]', '[50, 59]', '[60, 69]', '[70, 79]', '[80, 89]']
13
14# Age column: distributions, central values, dispersions and ranges
15age_stats = df['Age'].describe()
16age_bins = pd.cut(df['Age'], bins=bins, labels=labels, right=False)
17age_counts = age_bins.value_counts().sort_index()
18
19# Frequency counts for the 'Gender' column
20gender_counts = df['Gender'].value_counts()
21
22# Creating a DataFrame to display age and gender statistics
23summary_age_gender = pd.DataFrame({
24 "Age Statistics" : age_stats,
25 "Age Distribution": age_counts,
26 "Gender Distribution": gender_counts.reindex(['Male', 'Female', 'Other'], fill_value=0)
27})
28
29# Replace NaN with blank for cleaner look in the final display
30summary_age_gender.fillna(' ', inplace=True)
31
32# Output the results
33print(summary_age_gender)3. Who was their Croatian ancestor?
4. Where in Chile do they live?
1# Exploratory data analysis of ancestry and location
2
3# Load the cleaned data
4df = pd.read_excel('Cleaned_Survey_Data.xlsx')
5
6# Translate 'Ancestor' column from Spanish to English
7ancestor_translation = {
8 'Padre/Madre': 'Father/Mother',
9 'Abuelo/Abuela': 'Grandfather/Grandmother',
10 'Bisabuelo/Bisabuela': 'Great-Grandfather/Great-Grandmother',
11 'Tatarabuelo/Tatarabuela': 'Great-Great-Grandfather/Great-Great-Grandmother'
12}
13df['Ancestor'] = df['Ancestor'].map(ancestor_translation)
14
15# Frequency counts for the 'Ancestor' column
16ancestor_counts = df['Ancestor'].value_counts()
17
18# Frequency counts for the 'Location' column
19location_counts = df['Location'].value_counts()
20
21# Create summary DataFrame for displaying the statistics
22summary_ancestry_location = pd.DataFrame({
23 "Ancestor Distribution": ancestor_counts,
24 "Location Distribution": location_counts
25})
26
27# Display the DataFrame to ensure it appears correctly
28print(summary_ancestry_location)When observing the responses to the last two questions, two things caught my attention: first, the clearly large generational distance most of the respondents had from their Croatian ancestors, and second, the territorially scattered responses. To dig into the first one, I started by establishing four different generations of descendants by categorizing them according to their Croatian ancestors. In this way, I could ask the data for more specific insights into each generation’s experience.
1## Understanding the sample
2
3# Exploratory data analysis of generational diversity
4
5# Load the cleaned data
6df = pd.read_excel('Cleaned_Survey_Data.xlsx')
7
8# Map 'Ancestor' descriptions to generational labels
9generation_map = {
10 'Padre/Madre': 'Generation 2', # Father/Mother
11 'Abuelo/Abuela': 'Generation 3', # Grandfather/Grandmother
12 'Bisabuelo/Bisabuela': 'Generation 4', # Great-Grandfather/Great-Grandmother
13 'Tatarabuelo/Tatarabuela': 'Generation 5' # Great-Great-Grandfather/Great-Great-Grandmother
14}
15
16# Apply the mapping to the 'Ancestor' column
17df['Generation'] = df['Ancestor'].map(generation_map)
18
19# Count the number of respondents in each generation
20generation_counts = df['Generation'].value_counts()
21
22# Output the first few rows to verify the transformation
23print(generation_counts)
24
25# Save the dataframe with new column
26df.to_excel('Survey_with_Gen.xlsx', index=False)In the second case, I visualized the responses on a map of Chilean territory —from an open-source governmental website— by using the filtered responses about location from the previous and then creating a dictionary of coordinates containing the number of responses in each city. Therefore, the visualization also showed the frequency of responses. This helped to establish a correlation between the respondents’ territorial dispersion, the centers of the arrival of the historical migration, and the existence of Croatian clubs today.
1# Visualizing territorial diversity
2
3import geopandas as gpd
4import numpy as np
5import matplotlib.pyplot as plt
6from shapely.geometry import Point
7
8# Load the shapefile containing Chile's regions.
9regions = gpd.read_file('Regional.shp')
10regions = regions.to_crs("EPSG:4326")
11
12# Define a single color for all points
13point_color = '#c5283d'
14
15# Dictionary of city coordinates and the number of respondents in each city
16location_data = {
17 "Santiago": (-33.4489, -70.6693, 71),
18 "Punta Arenas": (-53.1638, -70.9171, 50),
19 "Viña del Mar": (-33.0153, -71.5505, 7),
20 "Antofagasta": (-23.6509, -70.3975, 7),
21 "La Serena": (-29.9027, -71.2519, 6),
22 "Concepción": (-36.8261, -73.045, 5),
23 "Coquimbo": (-29.9533, -71.3395, 4),
24 "Iquique": (-20.2208, -70.1431, 3),
25 "Linares": (-35.8467, -71.6006, 2),
26 "Ovalle": (-30.5983, -71.2003, 2),
27 "Arica": (-18.4783, -70.3126, 2),
28 "Concón": (-32.9209, -71.5185, 2),
29 "Vallenar": (-28.5708, -70.7581, 2),
30 "Puerto Natales": (-51.7333, -72.5000, 2),
31 "Porvenir": (-53.3048, -69.0567, 2),
32 "Copiapó": (-27.3668, -70.3319, 1),
33 "Chaitén": (-42.9167, -72.7167, 1),
34 "Chiloe": (-42.6000, -73.9500, 1),
35 "Valparaíso": (-33.0472, -71.6127, 1),
36 "Calama": (-22.4544, -68.9292, 1),
37 "Osorno": (-40.5739, -73.1336, 1),
38 "Los Ángeles": (-37.4697, -72.3537, 1),
39 "Mulchen": (-37.7157, -72.2304, 1),
40 "Temuco": (-38.7396, -72.5984, 1),
41 "Puerto Varas": (-41.3167, -72.9833, 1),
42 "Frutillar": (-41.1267, -73.0431, 1)
43}
44
45# Flatten the list of coordinates and introduce jitter
46jittered_points = []
47for city, (lat, lon, count) in location_data.items():
48 for _ in range(count):
49 # Add a small random number to each coordinate
50 jittered_lat = lat + np.random.uniform(-0.40, 0.40)
51 jittered_lon = lon + np.random.uniform(-0.40, 0.40)
52 jittered_points.append(Point(jittered_lon, jittered_lat))
53
54# Create a GeoDataFrame with these jittered points
55gdf_jittered_responses = gpd.GeoDataFrame(geometry=jittered_points, crs="EPSG:4326")
56
57# Plotting
58fig, ax = plt.subplots(figsize=(10, 10))
59regions.plot(ax=ax, color='white', edgecolor='#d9cab3')
60
61# Plot each jittered point with specified color
62ax.scatter([point.x for point in gdf_jittered_responses.geometry],
63 [point.y for point in gdf_jittered_responses.geometry],
64 color=point_color, s=20, edgecolor='k', linewidth=0.2, alpha=0.60)
65
66plt.title('Locations of the survey respondents in Chile')
67
68# Save the figure as an SVG file
69plt.savefig('../chilemap.svg', format='svg')
70
71plt.show()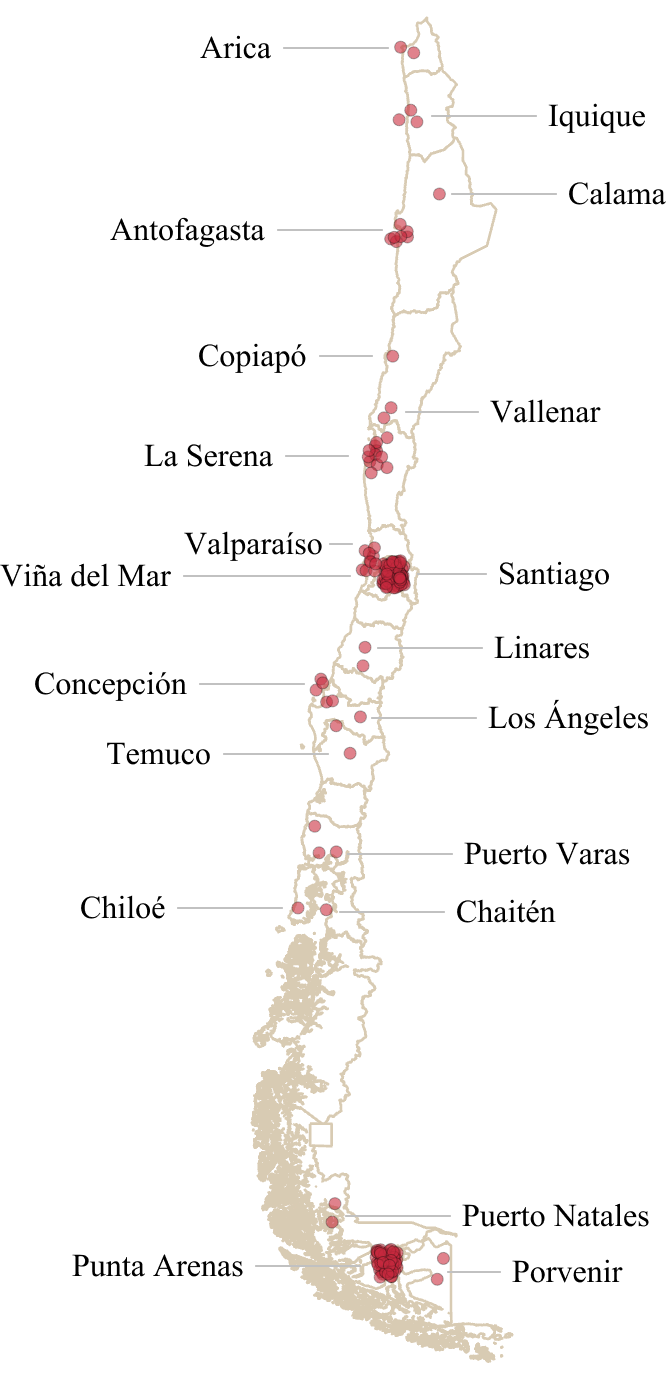
Figure 2. A map of continental Chile showing the geographical dispersion and frequency of responses received in the survey.
Generating insights
The final step in my analysis was to synthesize the data into coherent insights that address the research question regarding the interplay between citizenship policies and generational dynamics. Utilizing Python’s data manipulation libraries, I was able to identify patterns and trends that elucidate how changes in Croatian citizenship legislation have influenced identity perceptions and engagement among different generations and genders
1# Relationship between age and generation
2
3import pandas as pd
4import matplotlib.pyplot as plt
5
6# Excel into a DataFrame
7df = pd.read_excel('Survey_with_Gen.xlsx')
8
9# Filter out rows where generation is 'Husband's family'
10df_filtered = df[df['Generation'] != "Familia de mi marido"]
11
12# Creating a box plot to visualize age distribution within each generation
13plt.figure(figsize=(10, 6))
14df_filtered.boxplot(column='Age', by='Generation')
15plt.xlabel('Generation')
16plt.ylabel('Age')
17plt.xticks(rotation=0)
18plt.grid(False)
19plt.show()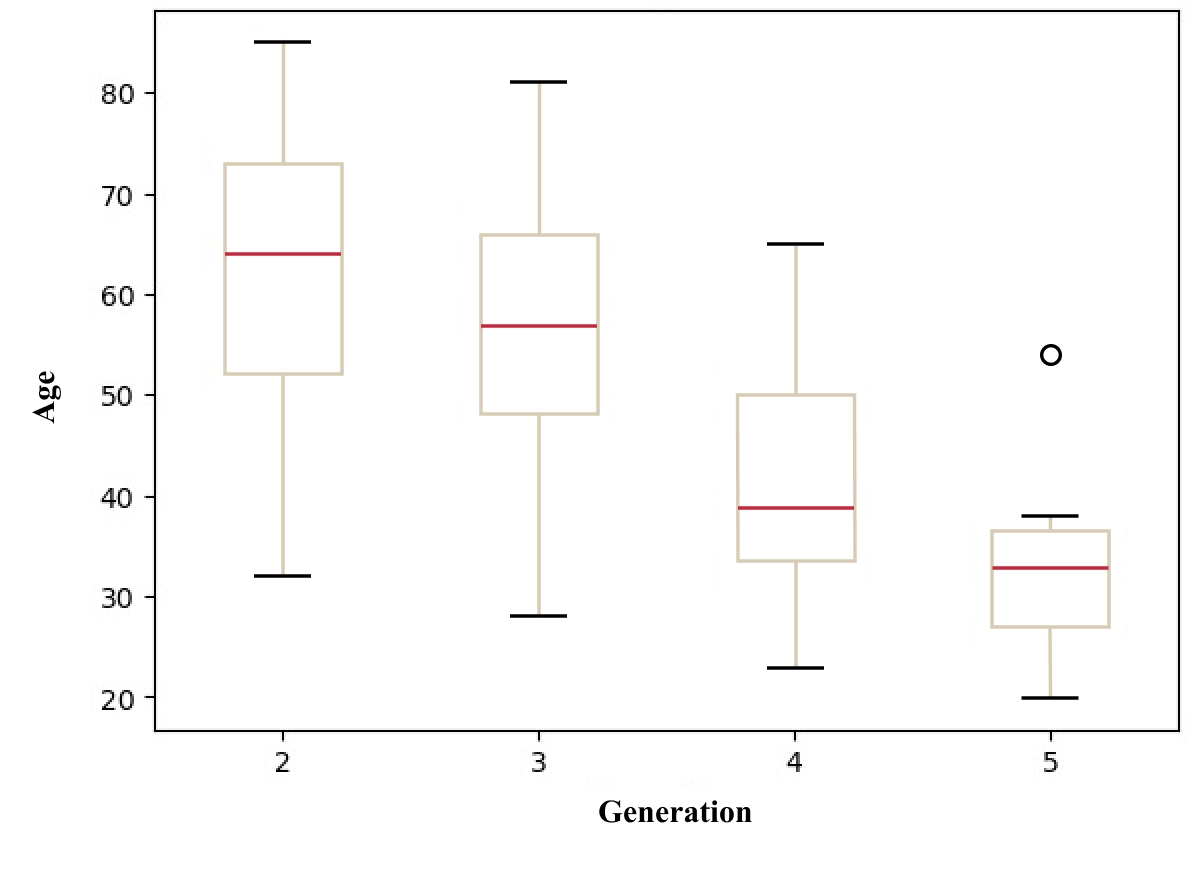
Figure 3. Boxplot of age distribution by migrant generation.
1# Relationship between awareness of policies and demographic markers
2
3file_path = 'Cleaned_Survey_Data.xlsx'
4df = pd.read_excel(file_path)
5
6# Create age ranges
7bins = [20, 30, 40, 50, 60, 70, 80, 90]
8labels = ['[20, 29)', '[30, 39)', '[40, 49)', '[50, 59)', '[60, 69)', '[70, 79)', '[80, 89)']
9df['AgeRange'] = pd.cut(df['Age'], bins=bins, labels=labels, right=False)
10
11# Group by age range, gender and policy awareness, then count occurrences
12awareness_by_age_gender = df.groupby(['AgeRange', 'Gender'])['Citizenship_Awareness'].value_counts().unstack()
13
14# Calculate percentages
15total_counts = awareness_by_age_gender.sum(axis=1)
16awareness_by_age_gender['% Females_Aware'] = (awareness_by_age_gender.xs('Femenino', level=1, drop_level=False)['Sí'] / total_counts.xs('Femenino', level=1)) * 100
17awareness_by_age_gender['% Males_Aware'] = (awareness_by_age_gender.xs('Masculino', level=1, drop_level=False)['Sí'] / total_counts.xs('Masculino', level=1)) * 100
18
19print(awareness_by_age_gender)| Age Range | Total | Female unaware | Female aware | % Females aware | Males unaware | Males aware | % Males aware | % Total unaware | % Total aware |
|---|---|---|---|---|---|---|---|---|---|
| 20-29 | 12 | 1 | 6 | 85.7% | 0 | 5 | 100% | 1 | 11 |
| 30-39 | 40 | 1 | 21 | 95.4% | 1 | 17 | 94.4% | 2 | 38 |
| 40-49 | 33 | 3 | 12 | 80.0% | 3 | 15 | 83.3% | 6 | 27 |
| 50-59 | 43 | 4 | 20 | 83.3% | 5 | 14 | 73.6% | 9 | 34 |
| 60-69 | 34 | 4 | 16 | 80.0% | 1 | 13 | 92.8% | 5 | 29 |
| 70-79 | 13 | 1 | 6 | 85.7% | 2 | 4 | 66.6% | 3 | 10 |
| 80-89 | 5 | 1 | 2 | 66.6% | 1 | 1 | 50.0% | 2 | 3 |
Table 1. Distribution of the sample according to age, gender, and awareness of Croatian citizenship policies.
One key finding was the variance in how different generations perceive and engage with their Croatian heritage. Younger generations appeared more receptive to the changes in citizenship policy, which aligns with their greater engagement in digital platforms for cultural exploration. This trend suggests a shift from a purely lineage-based identity towards a more proactive and choice-based connection with their heritage
1# Relationship between generation, citizenship status and influence of policies
2
3import pandas as pd
4import numpy as np
5
6# Load the data from Excel
7file_path = 'Survey_with_Gen.xlsx'
8df = pd.read_excel(file_path, usecols=['Generation', 'Citizenship_Status', 'Citizenship_Influence'])
9
10# Translate 'Citizenship_Status' values
11df['Citizenship_Status'] = df['Citizenship_Status'].replace({
12 'Sí': 'Yes',
13 'No': 'No',
14 'Estoy en proceso de solicitud': 'Applying'
15})
16
17# Translate 'Citizenship_Influence' values and fill blanks
18df['Citizenship_Influence'] = df['Citizenship_Influence'].replace({
19 'Sí': 'Yes'
20}).fillna(np.nan)
21
22# Group by 'Generation' and 'Citizenship_Status' and count occurrences
23gen_citizenship_counts = df.groupby(['Generation', 'Citizenship_Status']).size().unstack(fill_value=0)
24
25# Calculate the total responses for each generation
26gen_citizenship_counts['Total'] = gen_citizenship_counts.sum(axis=1)
27
28# Calculate the percentage of respondents who have Croatian citizenship or have applied for it
29gen_citizenship_counts['% Applied'] = (gen_citizenship_counts['Applying'] / gen_citizenship_counts['Total'] * 100).round(1)
30gen_citizenship_counts['% Yes'] = (gen_citizenship_counts['Yes'] / gen_citizenship_counts['Total'] * 100).round(1)
31gen_citizenship_counts['% No'] = (gen_citizenship_counts['No'] / gen_citizenship_counts['Total'] * 100).round(1)
32
33# Filter the DataFrame to include only 'Yes' and 'Applying' in 'Citizenship_Status'
34filtered_df = df[df['Citizenship_Status'].isin(['Yes', 'Applying'])]
35
36# Group by 'Generation', 'Citizenship_Status' and 'Citizenship_Influence' and count occurrences
37influence_counts = filtered_df.groupby(['Generation', 'Citizenship_Status', 'Citizenship_Influence']).size().unstack(fill_value=0)
38
39# Calculate the total number of respondents influenced by policy changes for each citizenship status
40influence_counts['Total Influenced'] = influence_counts.sum(axis=1)
41
42# Calculate the specific influence percentages for each category
43influence_counts['% Influenced'] = (influence_counts['Yes'] / influence_counts['Total Influenced'] * 100).round(1)
44influence_counts['% Not Influenced'] = (influence_counts['No'] / influence_counts['Total Influenced'] * 100).round(1)
45
46# Prepare separate DataFrames for Citizens and Applicants
47citizens_influence = influence_counts.xs('Yes', level='Citizenship_Status').add_prefix('% Citizens ').reset_index()
48applicants_influence = influence_counts.xs('Applying', level='Citizenship_Status').add_prefix('% Applicants ').reset_index()
49
50# Merge the influence data back with the main generation data
51combined_data = pd.merge(gen_citizenship_counts, citizens_influence, how='left', on='Generation')
52combined_data = pd.merge(combined_data, applicants_influence, how='left', on='Generation')
53
54print(combined_data)| Generation | Not citizens | % Not citizens | Citizens | % Citizens | Applicants | % Applicants | Total |
|---|---|---|---|---|---|---|---|
| 2 | 10 | 45.5% | 11 | 50.0% | 1 | 4.5% | 22 |
| 3 | 31 | 35.6% | 39 | 44.8% | 17 | 19.5% | 87 |
| 4 | 13 | 22.0% | 30 | 50.8% | 16 | 27.1% | 59 |
| 5 | 1 | 9.1% | 6 | 54.5% | 4 | 36.4% | 11 |
Table 2. Distribution of the sample according to generation and Croatian citizenship status.
| Generation | % Citizens | % Citizens influenced | % Citizens not influenced | % Applicants | % Applicants influenced | % Applicants not influenced | Total |
|---|---|---|---|---|---|---|---|
| 2 | 50.0% | 22.2% | 77.8% | 4.5% | 100% | 0% | 22 |
| 3 | 44.8% | 27.0% | 73.0% | 19.5% | 75% | 25.0% | 87 |
| 4 | 50.8% | 44.8% | 55.2% | 27.1% | 87.5% | 12.5% | 59 |
| 5 | 54.5% | 66.7% | 33.3% | 36.4% | 100% | 0% | 11 |
Table 3. Distribution of the sample according to generation, Croatian citizenship status, and influence of the change of policy for citizenship acquisition in 2020.